a.k.a. I F***ING HATE COMPUTERS WHEN THEY DON’T WORK RIGHT AND I CAN’T FIX THEM
Introduction
Up until now, I’ve almost always been running the DrProject server and the web browser to drive it on the same machine. For reasons I will not go into, I needed to run DrProject on an Ubuntu Linux installation on one computer and run the web browser on Windows on another computer. These two computers were on the same LAN. Let’s call these computers Lin and Win, respectively. Please don’t mind me personifying these machines.
When Firefox on Lin talked to the DrProject being hosted locally, everything worked fine. When Firefox on Win talked to the DrProject server on Lin, each page request took an excruciatingly long time to complete — something in the order of tens of seconds, rather than a second or two.
Coming up is a chronicle of following numerous false leads, running up and down the stairs, and diving into the depths of computing to debug problems at a low level. It unfolded over the course of about 3 hours, and is told in approximately chronological order.
Sanity checks
First, I tried accessing DrProject using Internet Explorer (on Win) to made sure that it wasn’t Firefox’s fault. Indeed, it wasn’t. Second, I tried accessing the server using a different Windows computer. Still no luck. I even tried using telnet[0] to access the HTTP server, where I still received a much-delayed response.
The puzzling thing was that Lin had no delays in accessing Internet resources, nor LAN resources (e.g. SMB into the Windows boxes).
In retrospect, if Windows was the problem, then I wouldn’t have caught it because I didn’t have another Linux computer on hand.[1]
Networking
 Maybe the network was to blame. All the computers in question were hooked up to a home router (“residential gateway”), and maybe it was causing problems. So I hooked up Lin and Win directly (on a single cable), and set up a static IP configuration for each. Even after back-and-forth tweaking and checking, this didn’t work. So I produced my old 10 Mb/s Ethernet hub, and connected these two computers to the hub. After more IP configuration tweaking, I finally got these computers to talk to each other again.
Maybe the network was to blame. All the computers in question were hooked up to a home router (“residential gateway”), and maybe it was causing problems. So I hooked up Lin and Win directly (on a single cable), and set up a static IP configuration for each. Even after back-and-forth tweaking and checking, this didn’t work. So I produced my old 10 Mb/s Ethernet hub, and connected these two computers to the hub. After more IP configuration tweaking, I finally got these computers to talk to each other again.
Mind you, all of this was complicated by the fact that Lin and Win were located one floor apart (yay for running up and down the stairs). Also, Lin had 2 network interfaces[2], and it was difficult to tell which one was mapped to device eth1 and which was mapped to eth2. I did try enabling and disabling each of these two interfaces.
… And there was no improvement in the Win-browser-talking-to-Lin-server lag.
Enter Wireshark (formerly Ethereal)

By now, I had dragged my friend Roy into the problem, as he is a Linux expert and a competent programmer. Other than mildly disagreeing about my choice of screen capture software, he suggested right off the bat that I analyze the network traffic with Wireshark, a packet sniffer. Since I used the older Ethereal back on Windows, I promptly set off to install Wireshark through the Debian package system without hesitation.
In the meantime, I tested using Win to connect a server socket on Lin to see if that was a problem. Using telnet[3] on Win and a netcat listener[4] on Lin, I saw no delay at all. That was weird. More and more, it looked like “tracd”, the built-in HTTP server in DrProject (inherited from Trac), was where I should have pointed my blame.
When Wireshark was downloaded and installed, I fired it up and captured the relevant network interface. I changed the DrProject server port from 8080 to the standard 80, and used the capture filter “tcp port http” to reduce the amount of data captured.
What immediately caught my eye was that while most rows were coloured green, quite a number of them were coloured black. Wireshark explained that the black rows represent packets whose TCP checksums were incorrect, giving the reason ‘maybe caused by “TCP checksum offload”?’.
Digging a bit deeper, these “black” packets were all from Lin to Win (but not all packets from Lin to Win were black), and they all had a size of 1514 bytes. But wait a minute! Isn’t it true that the Ethernet MTU is 1500 bytes? Wouldn’t it be bad to exceed the MTU? So I consulted Wikipedia and RFC 1191, but to no avail. They confirmed that the Ethernet standard MTU is 1500 bytes, but didn’t mention whether that included Ethernet headers or not.
 Through Wireshark’s detailed analysis of the raw 1514 bytes of data, I concluded that the 14 bytes were for Ethernet headers — 6 bytes for the MAC address of the sending machine, 6 bytes for the MAC address of the receiving machine, and 2 bytes for the EtherType[5]. With a bit of ifconfig wizardry[6], I set the MTU to 1486 bytes so that after adding the Ethernet headers, the total comes out to 1500 bytes. But I still had no luck with the slow connection problem!
Through Wireshark’s detailed analysis of the raw 1514 bytes of data, I concluded that the 14 bytes were for Ethernet headers — 6 bytes for the MAC address of the sending machine, 6 bytes for the MAC address of the receiving machine, and 2 bytes for the EtherType[5]. With a bit of ifconfig wizardry[6], I set the MTU to 1486 bytes so that after adding the Ethernet headers, the total comes out to 1500 bytes. But I still had no luck with the slow connection problem!
Following the TCP conversations through Wireshark did not prove of much use either. But I did see that it took about 10 seconds to respond to each HTTP connection.
strace
 Besides Wireshark, the other major recommendation from Roy was to run the DrProject server under strace. This program invokes another program, and traces (prints) all of the Unix system calls that the child program makes.
Besides Wireshark, the other major recommendation from Roy was to run the DrProject server under strace. This program invokes another program, and traces (prints) all of the Unix system calls that the child program makes.
Roy asked me to inform him of the last line printed by strace whenever the output stopped momentarily. I first noted that the trace stopped at “wait4(-1,” after starting the server. He said that it was because the target process was launching a child process.
I realized that to make this trace work, I had to disable DrProject’s auto-reloader. Which actually required me to hack the code, because it seemed the “–auto-reload” command line option was not parsed and handled correctly. In addition to that, the Python BaseHTTPServer was multi-threaded, so I had to invoke strace with the -f option, which resulted in significantly more trace output to the screen.
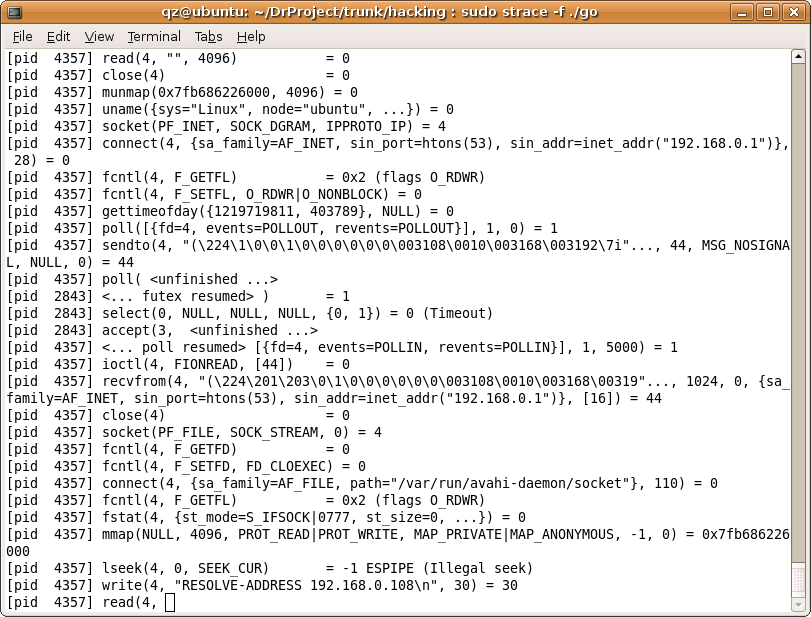
Finally, something interesting appeared. When Win talks to Lin, the trace stops at “read(4,” for a number of seconds, then resumes. Roy said that 4 is the file descriptor, and asked me to trace all the actions starting from the point where that particular FD (#4) was opened. This is what I found, with some irrelevant information removed:
socket(PF_FILE, SOCK_STREAM, 0) = 4
fcntrl(4, F_GETFD)
connect(4, {sa_family=AF_FILE, path="/var/run/avahi-daemon/socket"}, 110) = 0
lseek(4, 0, SEEK_CUR) = -1 ESPIPE (Illegal seek)
write(4, "RESOLVE-ADDRESS 192.168.0.108\n", 30) = 30
read(4, <-- Hangs here for a few seconds
If you ask me, that data being passed to the write system call looked like a DNS thing, or perhaps an ARP thing.
Avahi
With the evidence provided by strace in hand, Roy pointed to the Avahi Zeroconf software as the source of the problem. He asked me to toggle it — that is, start it if it was not running, and stop it if it was already running.
Stopping Avahi[7] and trying to access DrProject server on Lin from Win’s Firefox again… Success! W00t! 3 hours of intense troubleshooting had finally come to an end.
Conclusion
Was there a point in writing this? I don’t know. I don’t think you, the reader, can learn much from it. This article is comparable to a rant, with a hodge-podge of disconnected personal events and ideas. An honest and objective rant, though.
But I think this paints a picture of what computer problems look like, and how they are exhaustively troubleshooted and (hopefully) finally solved.
Oh yeah, and I took up about 1.5 hours of Roy’s time while he was at work. He has a flexible schedule as a software developer at a big company, so no worries. =P
Footnotes
Lin had the IP address 192.168.0.101.
Win had the IP address 192.168.0.108.
After Lin and Win could talk to each other, I would sit at Lin’s console and operate Lin while also hacking into Win using Remote Desktop Connection. So I didn’t run up and down between computers that much.
[0]: telnet 192.168.0.101 8000. Type “GET / HTTP/1.1 \r\n Host: 192.168.0.101 \r\n \r\n”.
[1]: Then again, I could have booted Ubuntu from a live CD.
[2]: One integrated on the motherboard, and one on a PCI card.
[3]: telnet 192.168.0.101 8000
[4]: netcat -l -p 8000
[5]: In this case, it was 0x0800 for IPv4.
[6]: ifconfig eth2 mtu 1486
[7]: sudo /etc/init.d/avahi-daemon stop